May 24 2021 Monday

Ransomware Prevention Part 3 - Patch Management
Part 3 - Patching
See here for the entire series of posts, if you are just stumbling onto these posts.
As I said in part one, these post are supposed to be helpful in giving you meaningful useful advice to prevent ransomware.
Recall from part two....
There are a multitude of reasons for this so if you need a refresher go read part 2, vulnerability scanning.
You're probably doing it wrong, if you're doing it at all
OK, so we're all on the same page, let's start off with a statement that is true in at least 80% of the organizations we get contracted in to help prevent ransomware:
Now don't get all upset and storm off in a huff. That's how you get ransomwared, letting your emotions get the better of you. Let's start with a series of statements that I hear about patching and work from there:
The above is my list, but if you don't believe me, go get the excellent ServiceNow "Cost and Consequences of Gaps in Vulnerability Response" report. It is free once you fill in the form. It's quite the read and does show that organizations can be overwhelmed by patching. On page 27 of the report (* - I'm using the average for the large and small organization numbers):
On the very next page:
Let's break that down:
That's some pretty eye popping numbers. Number 1 is handled by a vulnerability scanning (aka part 2 of this series), you can't patch what you don't know about. Number 2 is a failure of patch management.
The solution - automate, patch, report
So let's tackle each of the above "reasons" one at a time.
All 5 of the reasons organizations don't patch listed above can be mostly addressed by simply applying an automate, patch and report strategy to this issue. You want to manage the exceptions, the failures, the one-offs.
Automate
Now, I'm fully cognizant that not every single system can be fully automated for patch management. You have systems of such import that taking them down every month maybe unacceptable. If that's the case then manage the risks. Or find ways around it. Clustering is a excellent solution where loads can be transferred to other systems while patching takes place.
You also don't need to patch everything at the same time. Do each Domain Controller on a different day. Do DMZ systems sooner than other less risky networks. Patch desktops overnight or on a weekend. Hopefully your solution can do off-network laptops. COVID has pretty much made that a requirement.
Here's an example of an automated patch schedule from ManageEngine's Desktop Central (MEDC, free for 25 devices or less) which can patch Windows, Mac and Linux OSes and a vast multitude of 3rd party applications:
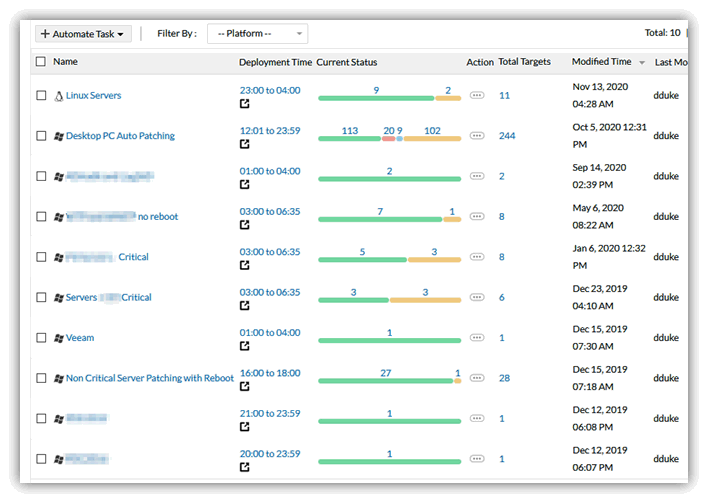
While the above doesn't show the days (grrr!) many of these happen over a weekend or overnight and are staggered. You can also see the current status of the entire patch group. In the above there are two Linux servers that are currently missing patches. I can either do them manually (SSH into them one at a time), create a patch job in MEDC and immediately patch these or just wait until the next patch window hits.
Additionally, you can automate the approval of patches. You're going to do them anyway, so why sit there an approve them. Some organizations require patches be tested on a subset of machines before being approved, and most good systems can do this, Orgs that to this subset way and get hit with ransomware pretty much immediately change to fully automated for all but a handful of systems.
Patch
Generally you want to patch often, patch quickly. Maybe for servers or other critical systems you wait a few days to see what Microsoft may have broken. It's essentially whatever allows you to sleep. Most desktops and laptops I would do immediately. The benefits far outweigh the risks.
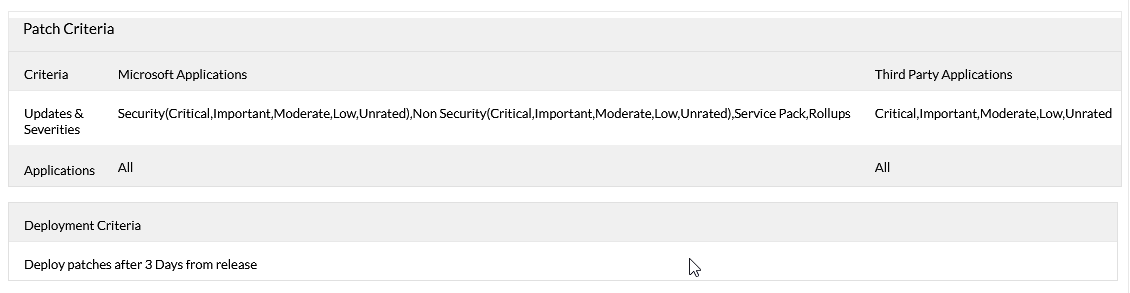
As to what you patch, again, it's more gut than anything else. I have generally shied away from updating BIOS with patch management (yes, some can do BIOS and driver updates) as it can cause problems (changing resolutions once users screens, causing a Bitlocker recovery, etc). Anything that the patch system says is critical, high or moderate is going in the next window. These would be automatically approved with zero human interaction (automate!). Anything not categorized, I'd maybe leave off unless my vulnerability scanner says otherwise (see what I did there?) or whatever allow me to sleep. Here's an example of an automatic non-critical server deployment from MEDC (these would be patched and rebooted on a weekend). Note the 3 day delay:
Report
If you already have an automated patch management system but you are not reporting from it or not looking at the reports then you are no better off than if you no patch management system at all. Because:
I see this all the time with organizations that use GPOs to set Windows Updates to install automatically or use WSUS. The lack of any discernible errors or warnings does not mean there are no errors or warnings. No, no, no, no. Patching (like vulnerability) is only as good as your monitoring of the system. Yes, 95% of systems are going to hum along, patch, reboot, rinse, repeat. But you will have several systems that have issues.
Issues could be a multitude of things, such as lack of disk space (so patches can't be copied, extracted, etc), the patch is corrupt, the patch needs to be downloaded to your management system because the patch is behind a pay-wall (anything Oracle). But unless you are monitoring and reporting from it, YOU WOULD NEVER KNOW UNTIL IT IS TOO LATE, You'll be one of the 60% who got hit despite a patch being available. Remember (and not just for patch management) automation is not absolution for you ensuring the automation is functioning correctly.
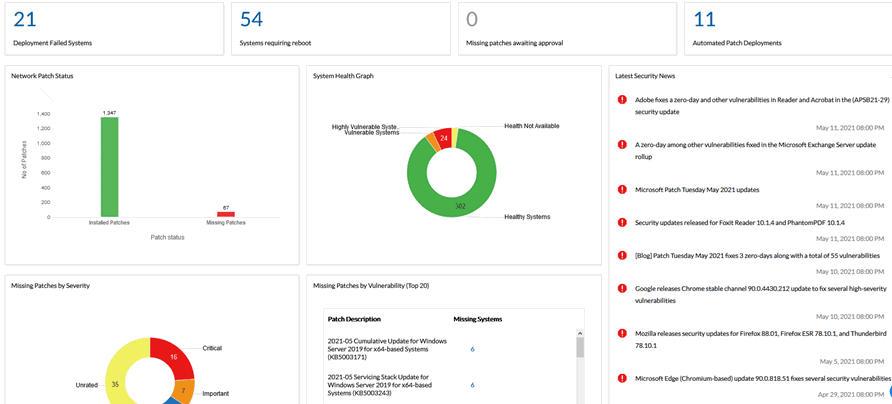
Here is a reporting screen from MEDC. There is a lot of instantly available information here. Also a security feed on the right so we can see what is coming:
Note this from the above:
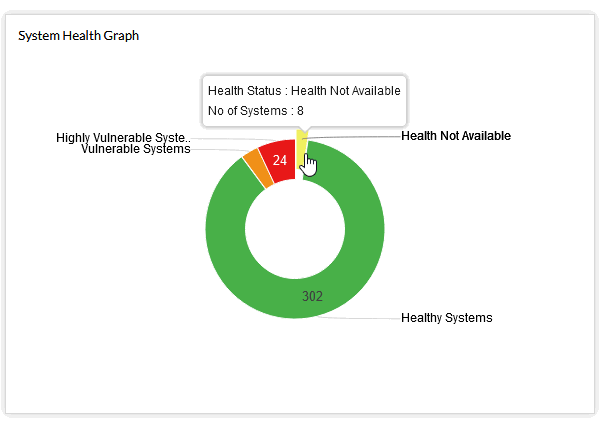
The yellow is "health not available", These need to be looked at as to why (especially if those systems are on),
Additionally, this:
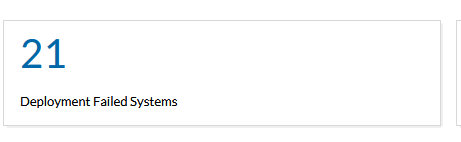
Now I have two areas to spend my time and find out why these two numbers are > 0. Out of the 345 systems managed here by MEDC I now have to manage 29 exceptions (8+21). This is a little over 8% of the systems (and most of the deployment failed are because the system was powered off when the scan was attempted, do in reality it probably < 4%).
Conclusion
With a bit of up-front effort, some good planning and a good patch management system, you can go a long way to helping prevent becoming one of the 60% of organizations who were breached via a patchable vulnerability.
See here for the entire series of posts, if you are just stumbling onto these posts.
As I said in part one, these post are supposed to be helpful in giving you meaningful useful advice to prevent ransomware.
Recall from part two....
Vulnerability scanning and analysis is not the same as patch management.
There are a multitude of reasons for this so if you need a refresher go read part 2, vulnerability scanning.
You're probably doing it wrong, if you're doing it at all
OK, so we're all on the same page, let's start off with a statement that is true in at least 80% of the organizations we get contracted in to help prevent ransomware:
You are doing patch management badly. Almost everyone does patch management badly.
Now don't get all upset and storm off in a huff. That's how you get ransomwared, letting your emotions get the better of you. Let's start with a series of statements that I hear about patching and work from there:
- Patching is risky.
- There are lots of patches.
- Patching is time consuming.
- We do patch, pinky swear (meaning they use Windows Updates).
- Prioritizing what needs to be patched first is difficult.
The above is my list, but if you don't believe me, go get the excellent ServiceNow "Cost and Consequences of Gaps in Vulnerability Response" report. It is free once you fill in the form. It's quite the read and does show that organizations can be overwhelmed by patching. On page 27 of the report (* - I'm using the average for the large and small organization numbers):
~60%* of data breaches occurred because a patch was available for a known vulnerability, but not applied,
On the very next page:
~46%* were unaware that the vulnerability existed before the breach.
Let's break that down:
- ~46%* did not know the vulnerability existed.
- ~40%* DID KNOW but had not patched the vulnerability.
That's some pretty eye popping numbers. Number 1 is handled by a vulnerability scanning (aka part 2 of this series), you can't patch what you don't know about. Number 2 is a failure of patch management.
The solution - automate, patch, report
So let's tackle each of the above "reasons" one at a time.
- Yes, patching is risky. Not patching is far riskier. 60% of data breaches reported in the ServiceNow report were tied to a known patchable, unpatched vulnerability. We all know that every 18 months or so (not including Feature Updates here, organizations really need to look at Windows 10 LTSC) you are going to have a bad few weeks where Microsoft breaks printing, etc. While not optimal, it's at least manageable. Far more so than a data breach or a ransomware incident.
- Yes, there are lots of patches. Too many for a mere human to RTFM and address. That's why you need automation. To not automate is to fail. Failure leads to fear. Fear leads to the dark side (quite literally in the case of Colonial Pipeline).
- Patching is not time consuming if you are automating and reporting. You should not need a human to interactively patch 95%+ of your systems. Manage the exceptions.
- While WSUS is technically a patch management system, it's pretty awful. I'm on the fence as to SCCM (System Center Configuration Manager) being a a significant upgrade. The world has moved on, it's not longer just Microsoft Windows, SQL Server and Office. Your patch management system also needs to be automated, heterogeneous and have an ever expanding ability to patch 3rd party applications and various Linux and Mac versions too. Have you ever installed VLC player on a system? If you have does your patch management system patch it? If it doesn't it should. Go read a few VLC security bullitins and you will soon fine the dreaded words "arbitrary code execution". Yes, you could build a package in SCCM, but using a human to create a software package (MSI, EXE, etc.) and figure out all the switches in order to patch a system is not automation. No, it's not. Get over yourself.
- Prioritization is only difficult if you are doing it manually. Again, a technician scouring the web for security bulletins and RTFMing them is not the way to do this. The vendors already already have a priority assigned when the patch is released. Or you could use the CVE/ CVSS number. Or a vulnerability scanner value (like Tenable's Vulnerability Priority Index, or VPR index). Either way, the heavy lifting is done for you. Stop trying to do it better. You won't succeed.
All 5 of the reasons organizations don't patch listed above can be mostly addressed by simply applying an automate, patch and report strategy to this issue. You want to manage the exceptions, the failures, the one-offs.
Automate
Now, I'm fully cognizant that not every single system can be fully automated for patch management. You have systems of such import that taking them down every month maybe unacceptable. If that's the case then manage the risks. Or find ways around it. Clustering is a excellent solution where loads can be transferred to other systems while patching takes place.
You also don't need to patch everything at the same time. Do each Domain Controller on a different day. Do DMZ systems sooner than other less risky networks. Patch desktops overnight or on a weekend. Hopefully your solution can do off-network laptops. COVID has pretty much made that a requirement.
Here's an example of an automated patch schedule from ManageEngine's Desktop Central (MEDC, free for 25 devices or less) which can patch Windows, Mac and Linux OSes and a vast multitude of 3rd party applications:
While the above doesn't show the days (grrr!) many of these happen over a weekend or overnight and are staggered. You can also see the current status of the entire patch group. In the above there are two Linux servers that are currently missing patches. I can either do them manually (SSH into them one at a time), create a patch job in MEDC and immediately patch these or just wait until the next patch window hits.
Additionally, you can automate the approval of patches. You're going to do them anyway, so why sit there an approve them. Some organizations require patches be tested on a subset of machines before being approved, and most good systems can do this, Orgs that to this subset way and get hit with ransomware pretty much immediately change to fully automated for all but a handful of systems.
Patch
Generally you want to patch often, patch quickly. Maybe for servers or other critical systems you wait a few days to see what Microsoft may have broken. It's essentially whatever allows you to sleep. Most desktops and laptops I would do immediately. The benefits far outweigh the risks.
As to what you patch, again, it's more gut than anything else. I have generally shied away from updating BIOS with patch management (yes, some can do BIOS and driver updates) as it can cause problems (changing resolutions once users screens, causing a Bitlocker recovery, etc). Anything that the patch system says is critical, high or moderate is going in the next window. These would be automatically approved with zero human interaction (automate!). Anything not categorized, I'd maybe leave off unless my vulnerability scanner says otherwise (see what I did there?) or whatever allow me to sleep. Here's an example of an automatic non-critical server deployment from MEDC (these would be patched and rebooted on a weekend). Note the 3 day delay:
Report
If you already have an automated patch management system but you are not reporting from it or not looking at the reports then you are no better off than if you no patch management system at all. Because:
If you are not looking, it's not working! Automation is not absolution!
I see this all the time with organizations that use GPOs to set Windows Updates to install automatically or use WSUS. The lack of any discernible errors or warnings does not mean there are no errors or warnings. No, no, no, no. Patching (like vulnerability) is only as good as your monitoring of the system. Yes, 95% of systems are going to hum along, patch, reboot, rinse, repeat. But you will have several systems that have issues.
Issues could be a multitude of things, such as lack of disk space (so patches can't be copied, extracted, etc), the patch is corrupt, the patch needs to be downloaded to your management system because the patch is behind a pay-wall (anything Oracle). But unless you are monitoring and reporting from it, YOU WOULD NEVER KNOW UNTIL IT IS TOO LATE, You'll be one of the 60% who got hit despite a patch being available. Remember (and not just for patch management) automation is not absolution for you ensuring the automation is functioning correctly.
Here is a reporting screen from MEDC. There is a lot of instantly available information here. Also a security feed on the right so we can see what is coming:
Note this from the above:
The yellow is "health not available", These need to be looked at as to why (especially if those systems are on),
Additionally, this:
Now I have two areas to spend my time and find out why these two numbers are > 0. Out of the 345 systems managed here by MEDC I now have to manage 29 exceptions (8+21). This is a little over 8% of the systems (and most of the deployment failed are because the system was powered off when the scan was attempted, do in reality it probably < 4%).
Conclusion
With a bit of up-front effort, some good planning and a good patch management system, you can go a long way to helping prevent becoming one of the 60% of organizations who were breached via a patchable vulnerability.


