July 15 2021 Thursday

Ransomware Prevention Part 8 - Backup and Recovery
Part 8 - Backup and recovery
See here for the entire series of posts, if you are just stumbling onto these posts.
As I said in part one, these post are supposed to be helpful in giving you meaningful useful advice to prevent ransomware.
This post is a bit different from the other posts, in that the previous 7 parts were tools and techniques to help prevent the attacks from ever happening (aka the best case scenario). Even if you follow all 7 posts down to the letter, there is still a possibility ransomware will get through your (now) multi-layered defenses. After all you have to be correct every time for everything. Mr and Mrs Hacker only have get it correct once. So plan for the worst and hope for the best. Not the other way round. So this post will cover how to actually put your organization in a place to recover as best as possible were the unthinkable to happen.
While you could pay the ransom, the Sophos - State of Ransomware 2021 report indicates only 8% of paying victims claimed to recover everything. 4% got nothing at all for their payment. On average only 65% of data is restored after an ransomware incident after paying the ransom, so one third of the data is gone, like the snap in Avengers: Infinity Wars, but for data. The average ransom payment was $170,404 USD. But the entire bill for rectifying the attack comes in at a whopping $1,850.000 USD.
What I'm about to cover cannot be done with a $100 Microcenter USB external drive and Windows Backup (well, maybe it can, but it shouldn't). Yes, for real backup and recovery build outs can be relatively expensive, but they are far, far less expensive than the average $1,850,000 that it currently costs were you to pay up and all the other things you now have to fix. And once you get hit, YOU WILL BE DOING THIS ANYWAY, so make the argument to do it now. It's not if you will get hit, it's when. And just because you have been hit doesn't mean you won't get hit again. I really wish they'd spend more time on probability in math(s) class.
Alas, sometimes you need a really bad experience to understand the obviously (now with the benefit of hindsight) stupid things you previously did. Exhibit number 1:

So let me start the meat of this post with the most important thing you will ever read in terms of recovering from a ransomware attack.....
No, I'm serious....this includes password and decryption keys as well. So once again, to the chorus.....
Never. Ever. The stories I have heard....."we had backups but they got encrypted as well"...."we had off-site backups and we even encrypted them for reason x,y,z, however the the private key/password (usually just a text file stored in a "secure" IT Windows file share) was encrypted by the ransomware so our backups are useless". It goes on and on and on. It's extremely common for an organization who gets ransomwared who also has backups that are about as useful as an ashtray on a motorbike. Far more common than you would ever imagine. So plan. And have a plan for when the plan won't work. Print actual copies of any keys you use and put them in a very safe place. Make sure you are not the only one who knows them.
Don't be the guy above that puts temporary hose ramps on a train track. Let's try to save you from that, eh?
For the most part this article will cover Veeam, mainly because of all the systems I've used, it's the easiest and does what it says. You solution du-jour may or may not be able to do the following. If it can't consider changing.
Also this is backup and recovery. Not high availability. Those are two very different things that are != (or <>) to each other at all. While a given product maybe able to do both, I'm not covering both here. HA is a paying gig and track down Lisa if you're interested in that.
Now for the second most important thing to understand about backups.....automate. When humans are involved with backups they fail. All the time. When humans are not involved with backups they fail far less often.
Recognize that not everything needs to be backed up and recoverable
There is some stuff is critical to your organization. Without it you simply cannot function. Back those up. Everything else is optional and is a function of cost vs PIA to rebuild it. For example, SQL servers and AD, sure. But if I had a pretty sizable Tenable install with one or more Nessus Linux scanners feeding it, do I really need to backup *all* the Nessus scanner devices? I would argue no. The value is in the Tenable reports that are harvested from the Nessus scanners. I can rebuild the Nessus scanners at a later date, or just back up one or two of them. Needless to say, the more you back up the more time it takes. Additionally you are taking precious backup resources from other more critical systems.
Frequency and Tagging
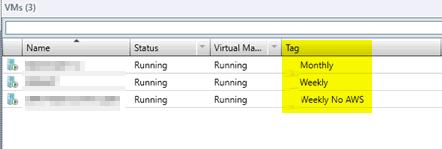
Give serious thought to the frequency you need to backup a given device. Break out your backups into these frequencies. Some stuff you want daily, others weekly or even monthly or quarterly. I may backup a given domain controller daily, but others maybe able to be backed up weekly. Also tag the stuff you don't want backed up. Then there is no confusion as to who is to blame when all hell breaks lose and that VM is not in the backup.
Tagging VMs is a way to combat the age old issue of forgetting to add something to the backup. Tagged objects can then be added automatically to backups. Both VMware and HyperV can do this (requiring vCenter and SCVMM respectively). In vCenter create folders for each backup frequency and add a tag to that folder and move VMs to the required folder. Then have Veeam back up that tag. SCVMM is much less user-friendly as you have to tag each VM independently.
Here's a vCenter folder tagged (meaning everything in that folder is also dynamically tagged when Veeam comes looking):
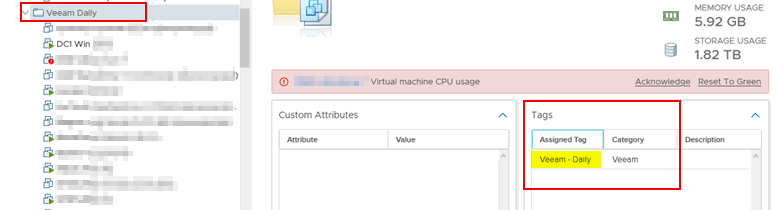
And here is the corresponding Veeam job that adds VMs that match the tag at every execution. Truly dynamic and now you don't need to edit your backup job everytime someone adds a VM. Simply move the VM to the required folder in vCenter and the next time that job runs, the new VM is added to the backup.
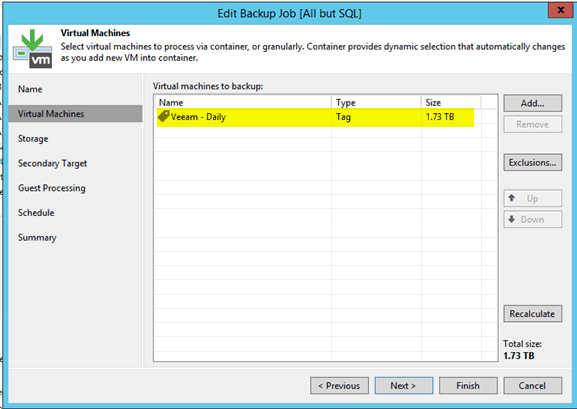
SCVMM is a per VM setting, but Veeam is still the same, dynamically adding VMs with associated tag at backup execution time. You cannot set this in HyperV settings, only in SCVMM settings:
Don't forget to backup assets that you will need *during* the recovery. Your PC for example. Also backup and store off-disk the Veeam configuration. You really don't want to have to install a new Veeam server and have it index all the backups across all your different storage tiers. That can add a long time the recovery.
Yes, you do need three tiers of backups
Every knows this already, yet few do it. It's a bit like exercise, we all *know* we should do it and it's not a secret, but doing *it* is a whole different matter. Multi-tier backups are like that. We *know* to do. The majority just don't. And by multi-tier I don't just mean cloud. Cloud for restoring has significant issue which I'll get to later. Just don't go thinking you've avoided all the backup pitfalls by using cloud. Because you haven't.
So a Darren approve system would go something like this....
Backup Location 1: Local disk. Dedicated *only* to the backup system. Not on a shared SAN with everything else. That's simply moronic and your asking for trouble with that approach. Lots and lots of storage. For Veeam your going to want format the storage as ReFS. Local disk has lots of advantages:
It does have one pretty big disadvantage:
Build for restore speed
Look, once your hit and you are confident you have good, restorable backups, it's now a time sink, a waiting game if you will. Create restore job, wait, wait, wait. Create restore job wait, wait, wait. The shorter your restore time, the faster you'll be back up and running. So from a restore perspective build the fastest backbone you can. At a minimum I'm talking 10Gb. See 10Gb is literally 10x faster than 1Gb. In real life 10Gb is 5x to 7x faster than 1Gb. That is still a huge factor. See:
10TB restore at 1Gb = ~22 hours
10TB restore at 10Gb = ~4-5 hours
And trust me, when you get hit, 10TB is a tiny amount to restore. If you have 4 VMs hitting 10TB each, on a 1Gb network you'll be up in approx one work week. On a 10Gb network, that is now restored inside of a day.
So this brings me back to the woeful cloud speeds during a restore. Even if your cloud provider were to give you a 10Gb feed back (which I very, very much doubt), can your internet connection back feed that kind of speed through to your virtual hosts? This is why you want recents close at hand and on a very fast backbone.
Restore speed is why the idiot CEO of Colonial Pipeline paid the ransom, thinking that somehow paying for and getting a decryption key would be speedier than restoring the backups they were already restoring. It's CEOs like this one that make ransomware such a lucrative crime.
Did you backup the pre-detonated ransomware? Are you now going to inadvertently restore it?
One of the tricks the ransomware tricksty hobbittes have in their quiver is to let the encryption engine sit dormant for a period of time before detonating, in hopes of contaminating your backups, so when you restore, boom, another no good very bad day for you. While this is a risk for you, it's also a risk for them as the longer they delay their attack the more likely you are to discover it. pre-encryption. That's not to say it's not a real threat, because it is. And the backup vendors are now integrating scanning directly into the restore process to ensure you don't inadvertently reinfect yourself.
In Veeam's case this feature is called Veeam Secure Restore. There could be some setup involved depending on your requirements so make sure you know what they are before you need it. It will add time to the restore as the virtual disk is mounted and scanned prior to full VM restore, but if you need this level of assurance, it is now available.
Configs, keys and the like
This is where I now extol the virtues of the cloud. You want to backup any and all configuration settings that you may need during a restore. I strongly suggest they be kept in secure cloud location. For example. you can have Veeam backup it's own config DB, ship it via SFTP to a SAN, etc. then ship that off to an AWS bucket. There are a multitude of ways of doing this, but again, automate it. Humans are generally useless when it comes to backup tasks.
Monitor
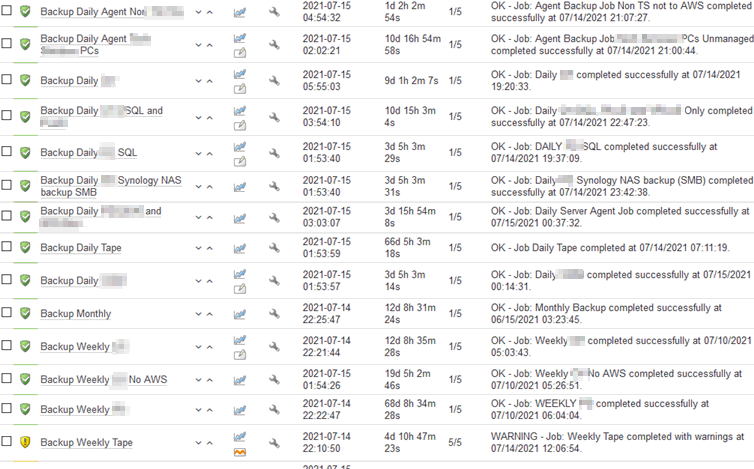
Yes, Veeam will send emails to you when a job succeeds, fails, burps, has a baby or bar mitzvah. etc. but you, as a general rule won't read them. So use something else to monitor your entire backup infrastructure, for instance Veeam One, or whatever takes your fancy. Here is OP5 (a Nagios derivative) that checks all kinds of jobs:
Protect your backup servers as if your naked pictures were on them
It should go without saying that even non-domain joined servers are still vulnerable. So protect them like nothing else in your data center. They should only allow the bare minimum of inbound connections, and should have firewall rules to prevent anything except management tools in. They should not be pingable, discoverable or any other such thing from anything other than a tiny handful of other devices. A completely separate subnet would be advisable to. Maybe even a hardware firewall between it and everything else. No amount of security around this is too much. Go big or go home.
Additionally, mandate MFA on the OS login (Duo, Okta, etc.) to prevent compromised account access. In short harden this server as you have no other.
Use dedicated log on accounts per backup technician (it's not AD joined remember?) with one-time, not used elsewhere passwords.
Conclusion
While I sincerely hope that you dear reader don't every have to recover from a ransomware incident the odds are not in your favor. This post (and the subsequent 7 other posts) can hopefully help make that no good very bad day just a day or two of downtime and a story to tell at conferences.
See here for the entire series of posts, if you are just stumbling onto these posts.
As I said in part one, these post are supposed to be helpful in giving you meaningful useful advice to prevent ransomware.
This post is a bit different from the other posts, in that the previous 7 parts were tools and techniques to help prevent the attacks from ever happening (aka the best case scenario). Even if you follow all 7 posts down to the letter, there is still a possibility ransomware will get through your (now) multi-layered defenses. After all you have to be correct every time for everything. Mr and Mrs Hacker only have get it correct once. So plan for the worst and hope for the best. Not the other way round. So this post will cover how to actually put your organization in a place to recover as best as possible were the unthinkable to happen.
While you could pay the ransom, the Sophos - State of Ransomware 2021 report indicates only 8% of paying victims claimed to recover everything. 4% got nothing at all for their payment. On average only 65% of data is restored after an ransomware incident after paying the ransom, so one third of the data is gone, like the snap in Avengers: Infinity Wars, but for data. The average ransom payment was $170,404 USD. But the entire bill for rectifying the attack comes in at a whopping $1,850.000 USD.
The average cost of rectifying a ransomware attack, considering downtime, people time, device cost, network cost, lost opportunity cost, ransom paid. etc. was US$1.85 million.
What I'm about to cover cannot be done with a $100 Microcenter USB external drive and Windows Backup (well, maybe it can, but it shouldn't). Yes, for real backup and recovery build outs can be relatively expensive, but they are far, far less expensive than the average $1,850,000 that it currently costs were you to pay up and all the other things you now have to fix. And once you get hit, YOU WILL BE DOING THIS ANYWAY, so make the argument to do it now. It's not if you will get hit, it's when. And just because you have been hit doesn't mean you won't get hit again. I really wish they'd spend more time on probability in math(s) class.
Alas, sometimes you need a really bad experience to understand the obviously (now with the benefit of hindsight) stupid things you previously did. Exhibit number 1:
So let me start the meat of this post with the most important thing you will ever read in terms of recovering from a ransomware attack.....
Never have any of your backup infrastructure domain joined!
Never have any of your backup infrastructure domain joined!
Never have any of your backup infrastructure domain joined!
No, I'm serious....this includes password and decryption keys as well. So once again, to the chorus.....
Never have any of your backup infrastructure domain joined!
Never. Ever. The stories I have heard....."we had backups but they got encrypted as well"...."we had off-site backups and we even encrypted them for reason x,y,z, however the the private key/password (usually just a text file stored in a "secure" IT Windows file share) was encrypted by the ransomware so our backups are useless". It goes on and on and on. It's extremely common for an organization who gets ransomwared who also has backups that are about as useful as an ashtray on a motorbike. Far more common than you would ever imagine. So plan. And have a plan for when the plan won't work. Print actual copies of any keys you use and put them in a very safe place. Make sure you are not the only one who knows them.
Don't be the guy above that puts temporary hose ramps on a train track. Let's try to save you from that, eh?
For the most part this article will cover Veeam, mainly because of all the systems I've used, it's the easiest and does what it says. You solution du-jour may or may not be able to do the following. If it can't consider changing.
Also this is backup and recovery. Not high availability. Those are two very different things that are != (or <>) to each other at all. While a given product maybe able to do both, I'm not covering both here. HA is a paying gig and track down Lisa if you're interested in that.
Now for the second most important thing to understand about backups.....automate. When humans are involved with backups they fail. All the time. When humans are not involved with backups they fail far less often.
Recognize that not everything needs to be backed up and recoverable
There is some stuff is critical to your organization. Without it you simply cannot function. Back those up. Everything else is optional and is a function of cost vs PIA to rebuild it. For example, SQL servers and AD, sure. But if I had a pretty sizable Tenable install with one or more Nessus Linux scanners feeding it, do I really need to backup *all* the Nessus scanner devices? I would argue no. The value is in the Tenable reports that are harvested from the Nessus scanners. I can rebuild the Nessus scanners at a later date, or just back up one or two of them. Needless to say, the more you back up the more time it takes. Additionally you are taking precious backup resources from other more critical systems.
Frequency and Tagging
Give serious thought to the frequency you need to backup a given device. Break out your backups into these frequencies. Some stuff you want daily, others weekly or even monthly or quarterly. I may backup a given domain controller daily, but others maybe able to be backed up weekly. Also tag the stuff you don't want backed up. Then there is no confusion as to who is to blame when all hell breaks lose and that VM is not in the backup.
Tagging VMs is a way to combat the age old issue of forgetting to add something to the backup. Tagged objects can then be added automatically to backups. Both VMware and HyperV can do this (requiring vCenter and SCVMM respectively). In vCenter create folders for each backup frequency and add a tag to that folder and move VMs to the required folder. Then have Veeam back up that tag. SCVMM is much less user-friendly as you have to tag each VM independently.
Here's a vCenter folder tagged (meaning everything in that folder is also dynamically tagged when Veeam comes looking):
And here is the corresponding Veeam job that adds VMs that match the tag at every execution. Truly dynamic and now you don't need to edit your backup job everytime someone adds a VM. Simply move the VM to the required folder in vCenter and the next time that job runs, the new VM is added to the backup.
SCVMM is a per VM setting, but Veeam is still the same, dynamically adding VMs with associated tag at backup execution time. You cannot set this in HyperV settings, only in SCVMM settings:
Don't forget to backup assets that you will need *during* the recovery. Your PC for example. Also backup and store off-disk the Veeam configuration. You really don't want to have to install a new Veeam server and have it index all the backups across all your different storage tiers. That can add a long time the recovery.
Yes, you do need three tiers of backups
Every knows this already, yet few do it. It's a bit like exercise, we all *know* we should do it and it's not a secret, but doing *it* is a whole different matter. Multi-tier backups are like that. We *know* to do. The majority just don't. And by multi-tier I don't just mean cloud. Cloud for restoring has significant issue which I'll get to later. Just don't go thinking you've avoided all the backup pitfalls by using cloud. Because you haven't.
So a Darren approve system would go something like this....
Backup Location 1: Local disk. Dedicated *only* to the backup system. Not on a shared SAN with everything else. That's simply moronic and your asking for trouble with that approach. Lots and lots of storage. For Veeam your going to want format the storage as ReFS. Local disk has lots of advantages:
- Fast backups. The fastest of backups actually.
- Fast restores. You won't get this with cloud.
- Keep the most recent backups on local disk. This will save time and money when doing normal day-to-day restores of things that users delete. For me recents are 45 to 61 days, depending on your need.
- Disk is cheap to add to. Relatively speaking. Need more? Add disk shelves. Or Veeam servers. Or both.
It does have one pretty big disadvantage:
- It's online, so susceptible to attack. It can be ransomwared. Especially if you are a moron and leave it domain joined. Don't be a moron.
- Relatively OK speed and storage per tape (LTO8 is 12TB uncompressed per tape at 360MB/s....LTO10 and beyond will double the storage of each previous generation). You can have multiple autoloaders off one Veeam server.
- Offline. So extremely low risk of compromise. It's as close to air gapping as you can get and still have a usable backup system.
- Keep the most recent and then some. 90-180 days
- Can be shipped off-site. Try doing that with a disk shelf attached to a Veeam server.
- Great for long term storage.
- Can be made immutable. AWS for example can have Veeam backups made immutable for a period of time, so you can guarantee the backups have not been tampered with.
- Geographically diverse. Not really a ransomware advantage, but still....
- Cloud looks fast when you are backing up to it or moving your backups to it. This is generally because when you backup you are most often backing up incremental changes. These backup files tend to be a tiny fraction of the size that actual full backups would be. Yet when you get hit by ransomware and you have to restore, you are *actually* restoring full backups and not the much smaller incremental backup files. I cannot stress enough how difficult it is to restore a full environment from cloud backups in a timely manner. Basically you can't and it will take a whole lot longer then you ever imagined. It'll take many days to a few weeks. Remember one of the hidden costs of ransomware is the loss of employee productivity, A day is a long time. A week or weeks could put you under.
- It's also expensive to restore from cloud. But it is still way cheaper than paying the ransom.
Build for restore speed
Look, once your hit and you are confident you have good, restorable backups, it's now a time sink, a waiting game if you will. Create restore job, wait, wait, wait. Create restore job wait, wait, wait. The shorter your restore time, the faster you'll be back up and running. So from a restore perspective build the fastest backbone you can. At a minimum I'm talking 10Gb. See 10Gb is literally 10x faster than 1Gb. In real life 10Gb is 5x to 7x faster than 1Gb. That is still a huge factor. See:
10TB restore at 1Gb = ~22 hours
10TB restore at 10Gb = ~4-5 hours
And trust me, when you get hit, 10TB is a tiny amount to restore. If you have 4 VMs hitting 10TB each, on a 1Gb network you'll be up in approx one work week. On a 10Gb network, that is now restored inside of a day.
So this brings me back to the woeful cloud speeds during a restore. Even if your cloud provider were to give you a 10Gb feed back (which I very, very much doubt), can your internet connection back feed that kind of speed through to your virtual hosts? This is why you want recents close at hand and on a very fast backbone.
Restore speed is why the idiot CEO of Colonial Pipeline paid the ransom, thinking that somehow paying for and getting a decryption key would be speedier than restoring the backups they were already restoring. It's CEOs like this one that make ransomware such a lucrative crime.
Did you backup the pre-detonated ransomware? Are you now going to inadvertently restore it?
One of the tricks the ransomware tricksty hobbittes have in their quiver is to let the encryption engine sit dormant for a period of time before detonating, in hopes of contaminating your backups, so when you restore, boom, another no good very bad day for you. While this is a risk for you, it's also a risk for them as the longer they delay their attack the more likely you are to discover it. pre-encryption. That's not to say it's not a real threat, because it is. And the backup vendors are now integrating scanning directly into the restore process to ensure you don't inadvertently reinfect yourself.
In Veeam's case this feature is called Veeam Secure Restore. There could be some setup involved depending on your requirements so make sure you know what they are before you need it. It will add time to the restore as the virtual disk is mounted and scanned prior to full VM restore, but if you need this level of assurance, it is now available.
Configs, keys and the like
This is where I now extol the virtues of the cloud. You want to backup any and all configuration settings that you may need during a restore. I strongly suggest they be kept in secure cloud location. For example. you can have Veeam backup it's own config DB, ship it via SFTP to a SAN, etc. then ship that off to an AWS bucket. There are a multitude of ways of doing this, but again, automate it. Humans are generally useless when it comes to backup tasks.
Monitor
Yes, Veeam will send emails to you when a job succeeds, fails, burps, has a baby or bar mitzvah. etc. but you, as a general rule won't read them. So use something else to monitor your entire backup infrastructure, for instance Veeam One, or whatever takes your fancy. Here is OP5 (a Nagios derivative) that checks all kinds of jobs:
Protect your backup servers as if your naked pictures were on them
It should go without saying that even non-domain joined servers are still vulnerable. So protect them like nothing else in your data center. They should only allow the bare minimum of inbound connections, and should have firewall rules to prevent anything except management tools in. They should not be pingable, discoverable or any other such thing from anything other than a tiny handful of other devices. A completely separate subnet would be advisable to. Maybe even a hardware firewall between it and everything else. No amount of security around this is too much. Go big or go home.
Additionally, mandate MFA on the OS login (Duo, Okta, etc.) to prevent compromised account access. In short harden this server as you have no other.
Use dedicated log on accounts per backup technician (it's not AD joined remember?) with one-time, not used elsewhere passwords.
Conclusion
While I sincerely hope that you dear reader don't every have to recover from a ransomware incident the odds are not in your favor. This post (and the subsequent 7 other posts) can hopefully help make that no good very bad day just a day or two of downtime and a story to tell at conferences.


